论文题目: Cross-lingual Transfer Learning for Multilingual Task Oriented Dialog
作者:Sebastian Schuster, Sonal Gupta, Rushin Shah, Mike Lewis
发表情况:NAACL-HLT 2018
1 | @inproceedings{Schuster2018CrosslingualTL, |
1. 问题描述
在AI对话系统中,首先要进行的工作往往是进行用户意图识别(intent detection)和槽语义识别(slot filling)。由于这项任务需要对大量对话语料进行标注,数据比较难获取。因此,借助高资源(high-resource)语言的语料去训练模型,然后将模型应用于低资源(low-resource)语言中,成为一种可行的方法。然而这种方法依赖多语训练语料。文章解决了两个问题:
多语训练语料匮乏的问题;
跨语言训练的方法问题。
2. 论文贡献
- 构建了一个新的跨语言数据集,共有 57k 标注语料,包括英语(43k)、西班牙语(8.6k)和泰语(5k)三种语言;
- 利用构建的数据集,验证了以下三种方法的效果:
- 1,直接将高资源语言翻译为低资源语言进行训练;
- 2,使用跨语言预训练词向量进行训练;
- 3,提出一种新的跨语言编码器,用于获取输入序列中各个词语的上下文表示(contexual representation)。
3. 主要方法
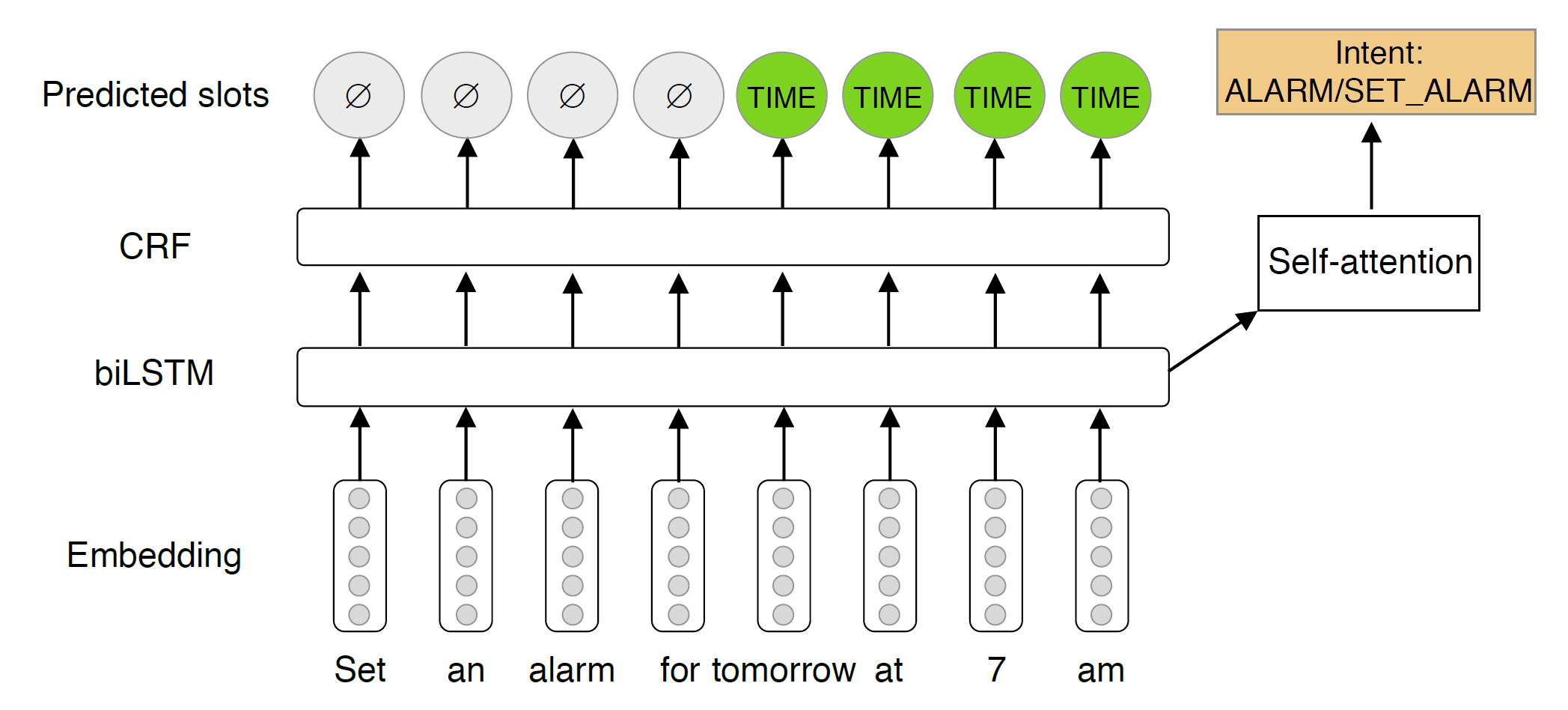
论文中使用的模型比较简单,如上图所示。不同训练策略的区别在于编码器所使用的数据和词向量,有以下几种:
- Target only:仅使用低资源语言数据;
- Target only with encoder embeddings:仅使用低资源语言数据,并使用预训练的编码器获得词向量;
- Translate train:使用Facebook机翻系统,将英语语料(高资源语言数据)翻译为低资源语言,然后结合原有的低资源语言数据进行训练,需要注意的是 slot 标注也通过注意力权重进行了映射;
- Cross-lingual with XLU embeddings:使用预训练跨语言词向量 MUSE,同时使用两种语言进行训练;
- Cross-lingual with encoder embeddings:使用预训练的编码器获得词向量,并同时使用两种语言同时进行训练。
这里的 encoder embeddings,我的理解是类似于 ELMo,先使用一个预训练的编码器获取到输入序列中每个词语的向量,然后再将这些向量作为模型输入。论文中,除西语使用了ELMo外,还涉及其他三种模型:
- CoVe:McCann 等人 2017 年提出的方法,类似于2018年发表的 ELMo,CoVe 使用机器翻译进行预训练,然后将 Encoder 用于其他任务上;
- Multilingual CoVe:将预训练方式改变为多语预训练,具体来讲,若训练英语-西语预训练模型,预训练模型可以将英语翻译为西语,也可以将西语翻译为英语。翻译方向取决于解码器中与语言相关的初始token;
- Multilingual Cove with autoencoder:在Multilingual CoVe的基础上,解码器的输出可以为目标语言的翻译文本,也可以为源语言的原始句子。以英语-西语为例,模型可以将英语翻译为对应的西语,也可以输出英语原始句子;同样,模型也可以将西语翻译为英语,也可以输出西语原句。翻译方向还是取决与解码器的 init token。
需要注意的是,在使用XLU embeddings 和 encoder embeddings 时,论文将其与随机初始化的词语向量拼接作为模型输入的向量。在训练过程中,仅调整随机初始化的词向量部分。
4. 论文亮点
- 论文提出的结合autoencoder的多语预训练方法比较新颖,不过现在我们有 Cross-lingual Language Model Pretraining 了;
- 论文针对不同的训练策略进行了大量的分析。

