这篇和跨语言多语任务型对话那篇都是跨语言相关的论文,作者都姓 Schuster,我还以为是同一个人来着……囧
论文题目:Cross-Lingual Alignment of Contextual Word Embeddings, with Applications to Zero-shot Dependency Parsing
作者:Tal Schuster, Ori Ram, Regina Barzilay, Amir Globerson
发表情况:NAACL-HLT 2019
1 | @inproceedings{Schuster2019CrossLingualAO, |
1. 问题背景
上下文相关的词向量(contextual embedding),如 ELMo,相比于静态的词向量可以包含更多的语义信息。但对于一个词来说,其上下文相关词嵌入是动态的,随上下文的变化而改变。目前的方法,如 MUSE 可以将一种语言的向量空间映射到另一种语言的向量空间,但仅限于静态词向量。对于ELMo产生的上下文相关,目前则没有很好的跨语言迁移方法。
2. 论文贡献
- 提出了数种新的对上下文相关词向量进行跨语言映射的方法;
- 将提出的方法应用到了多语依存句法分析任务中。
3. 主要方法
背景
论文首先定义了锚点的概念。对于词语 $i$ 在上下文 $c$ 中的向量表示集合 $e_{i,c}$,锚点向量为其平均值,即:
而向量空间对齐的方法,就是找到向量空间之间的映射矩阵,即:
中的$W^{s\to{t}}$。
观察
作者首先对ELMo词向量进行了观察,发现基本存在两种情况:
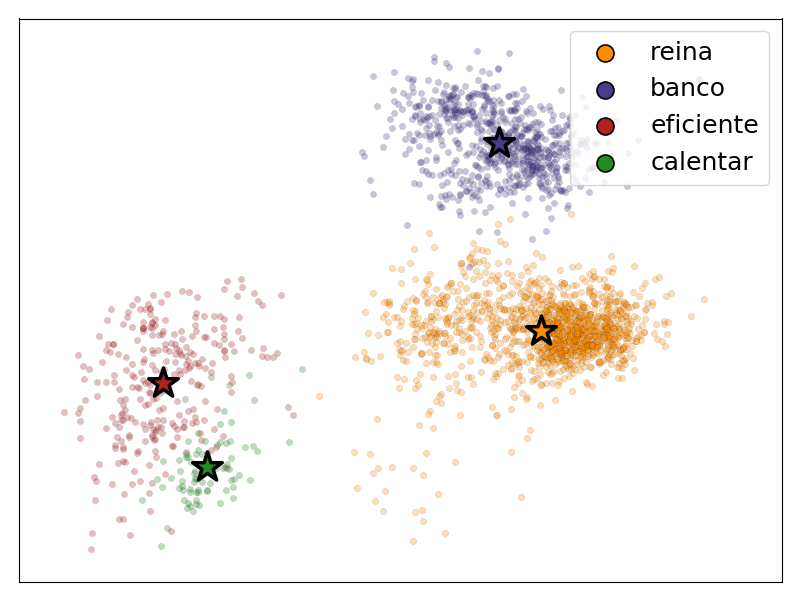
第一种,如图1所示,对于一个词语的所有词向量来说,其锚点向量大致处于点云中心。从直觉上,对于词语 $i$ 的锚点向量 来说,它与向量 $e_{i,c}$的距离应当比与另一个词语 $j$ 的锚点向量 $\bar{e}_j$ 的距离近。实际统计结果符合这样的直觉,如下表所示。


第二种,对于同音异义词来说,同一个词语点云可能较为分散。表1也表明,同音异义词之间的向量偏移(0.21)比其他词语之间略大,但相比于不同词语(0.85)仍然很小。所以,使用均值方法计算的锚点向量仍然可以作为一个词语点云的代表。
方法
在对上下文无关词向量(context-independent embeddings)进行跨语言映射时,存在有监督和无监督两种方法。
有监督学习方法要求有一个从源语言 $s$ 到目标语言 $t$ 的对应词表 ${(e_i^s, e_i^t)}$ ,按照如下公式学习映射矩阵:
无监督方法不需要词表,MUSE首先使用对抗学习方法进行训练,使用判别器区分目标语言的向量和映射后的源语言向量;接着迭代地进行 refinement 过程,即迭代地利用现有的模型选取置信度较高的词语对构建词典,再利用构建好的词典重新学习映射矩阵。如下图所示:

对于上下文相关词向量(context-dependent embeddings),论文提出了三种不同的对齐方法:
- 有监督的锚点对齐:将锚点向量作为一个词语的词向量,应用上面所述的有监督学习方法进行学习;
- 无监督的锚点对其:类似地,将锚点向量作为一个词语地词向量,应用上述无监督学习方法进行学习;
- 无监督基于上下文地对齐:不适用锚点向量和词表,直接使用MUSE算法进行对齐学习;
两种无监督方法均再对抗学习后使用了 refinement。
此外,论文提出,对于低资源语言来说,可以现有数据较为稀疏,不足以训练一个语言模型(如ELMo)。这时,可以使用高资源语言和词语对齐表作为参照,帮助低资源语言的语言模型训练。假定有高资源语言 $t$ 和低资源语言 $s$,并且高资源语言 $t$ 已经有一个训练好的语言模型。对于词语 $i$,其在语言 $s$ 中的词向量为 $\boldsymbol{v}_i^s$,在目标语言中对应词与 $D(i)$。那么,在训练语言 $s$ 的语言模型时,加入以下正则项:
这里的 为语言模型的输入向量,$ \lambda_{anchor} $ 是经验参数。加入正则项后,可以:
- 防止模型过拟合,
- 提供一定程度上的源语言和目标语言向量空间的对齐。
4. 应用
论文将提出的跨语言向量映射方法应用到依存句法分析上,应用方法为:
- 将 ELMo 语言模型输出的向量使用映射矩阵映射到高资源语言的向量空间上
- 将在高资源语言上训练获得的模型参数,共享到所有语言上。
同样的方法也可以应用于其他任务。

