simhash是google用来处理海量文本去重的算法。 simhash可以将一个文档转换成一个64位的字节,暂且称之为特征字。判断文档是否重复,只需要判断文档特征字之间的汉明距离。根据经验,一般当两个文档特征字之间的汉明距离小于3, 就可以判定两个文档相似。《数学之美》一书中,在讲述信息指纹时对这种算法有详细的介绍。
0x001、原理
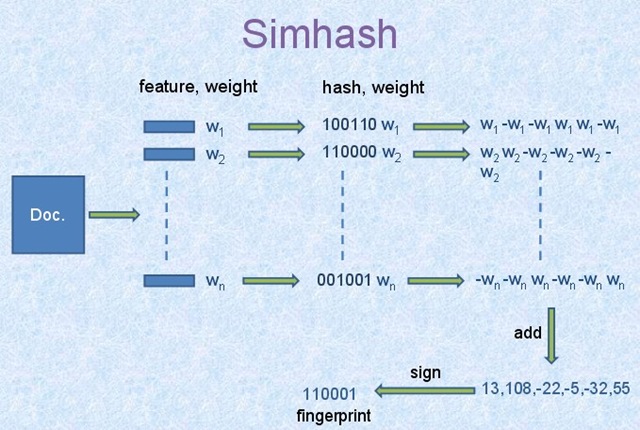
- 分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
- hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
- 加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
- 合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
- 降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
以上算法描述引用自1。
0x002、python中的simhash包
pip源中有数种simhash的实现,目前的工作中我使用的包就叫simhash,使用起来十分方便,直接使用pip就可以安装。
1 | pip install simhash |
一个简单的演示:
1 | import re |
上面的代码中,get_features()是一个十分naive的用于提取特征的函数,以3个character为一个特征。相当于分词。Simhash()可以接收一个字符串,也可以接收一个列表。代码演示来自于2。
计算出来simhash之后,可以很方便地计算两个simhash之间的距离。
1 | from simhash import Simhash |
以上。

